


この章を学ぶ前に必要な知識
効果
- 学習性能が向上
- あらかじめ人が設定しなくてはならないハイパーパラメータが減少
ポイント
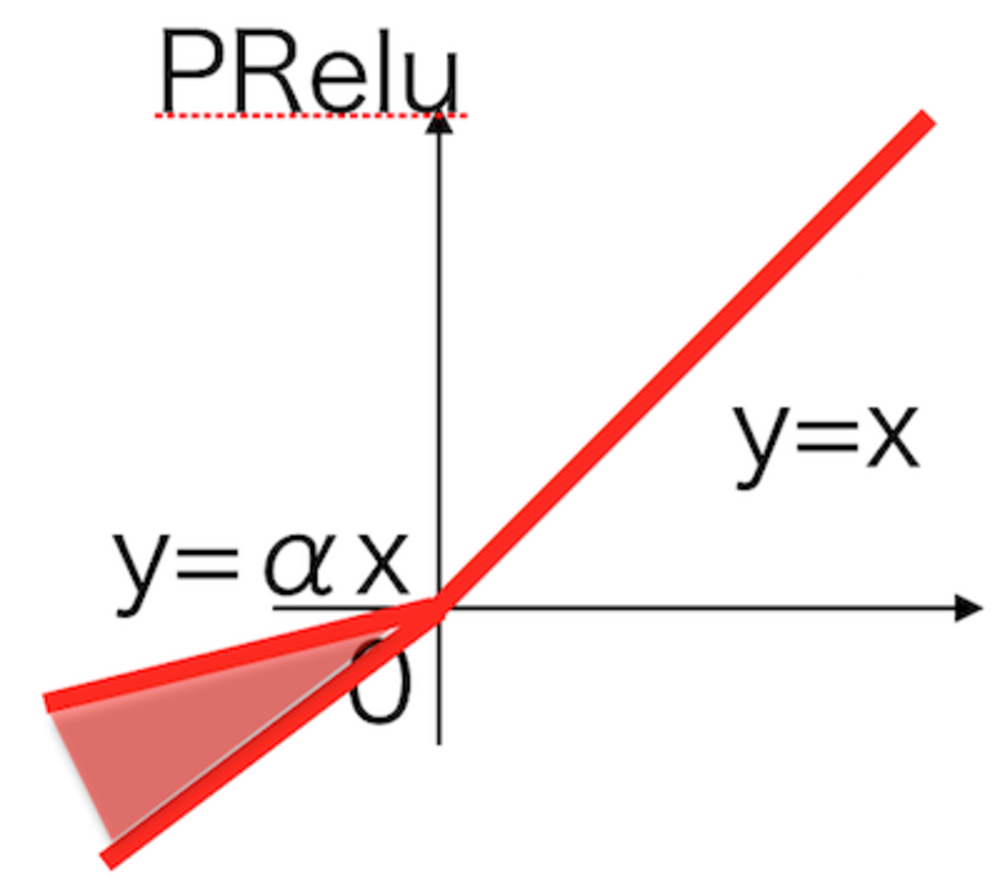
- LeakyReluを改良
- y=αxの傾きαのパラメータも学習
解 説
Relu活性化関数をベースに改良したLeakyReluを改良した活性化関数
LeakyReluの時に加えたxが負の時の傾きがハイパーパラメータになったため、
人手で設定するパラメータが増えてしまった。
この傾きαも含めて学習させることで、ハイパーパラメータを減らすとともに
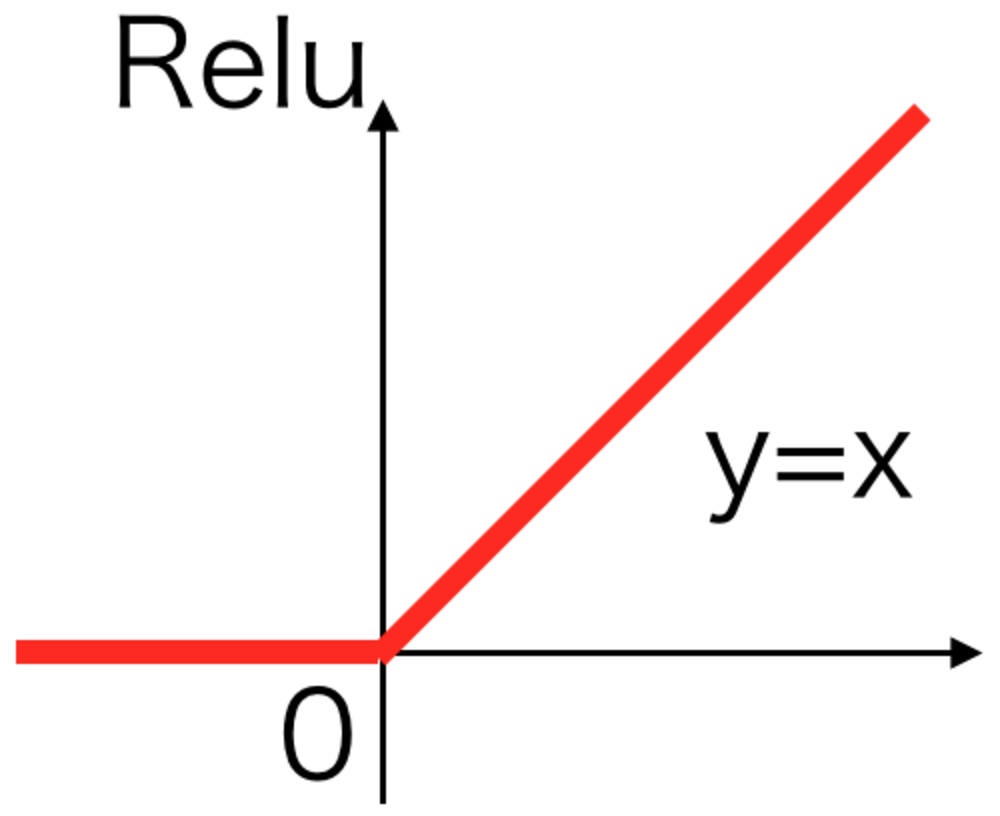
精度を向上させることができた。 | Relu活性化関数 |
\begin{eqnarray}
y =
\begin{cases}
x & ( x \geqq 0 ) \\
\alpha x & ( x \lt 0 )
\end{cases}
\end{eqnarray} | PRelu活性化関数
LeakyReluと見た目は同じだが、αも学習する対象 |
PReluの元論文をリンクしておきます。 | 外部リンク 元論文 |
この章を学んで新たに学べる
Comments