-
 @ThothChildren
@ThothChildren
- 2017.9.13
- PV 884
Relu活性化関数
ー 概要 ー
最も現在使われることの多い活性化関数。
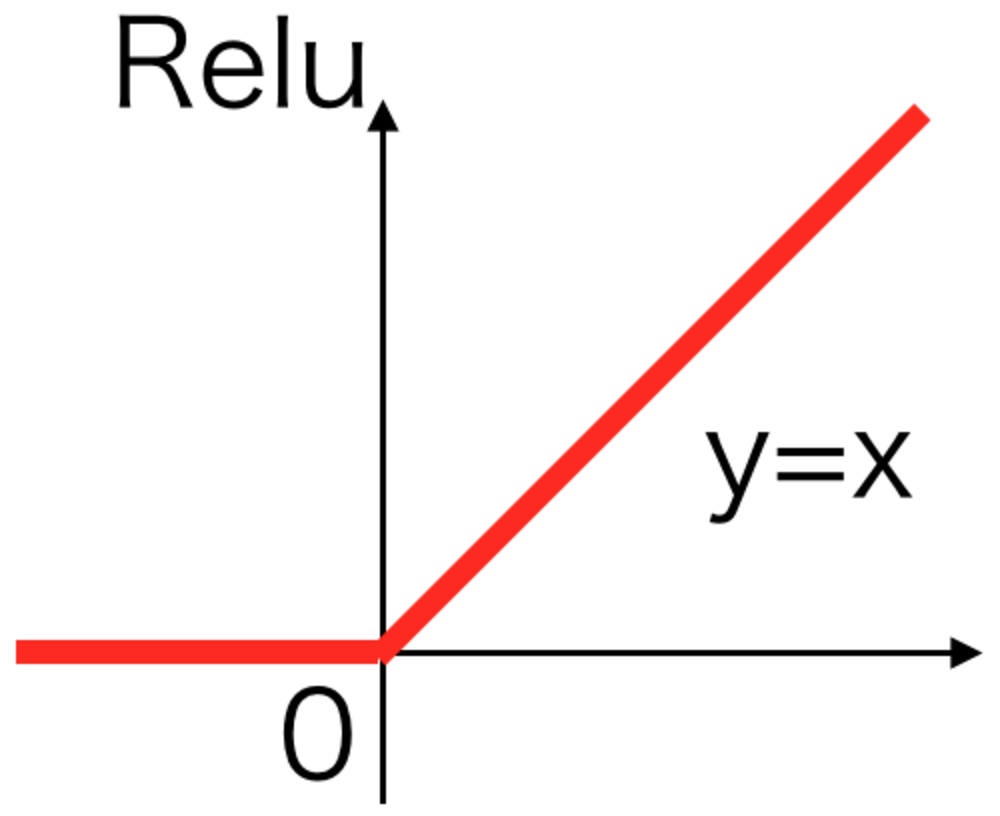
xが負のとき0それ以外は恒等関数.
シグモイドなどより計算が早いことが特徴.



この章を学ぶ前に必要な知識
効果
- 勾配が消失しない
- 学習が早い
ポイント
- Reluを微分するとxが正のとき1それ以外で0
- dead neuronの問題にはまると学習が停止して同じ値を出し続ける
- dead neuronを避けるためにELUやLeakyReluが使用される
解 説
1.Reluとは | |
Reluは現在のDeepLearningにおいて最も使用される活性化関数の一つとなっており、
以下のような形で記述される。 | Relu活性化関数とは |
\begin{eqnarray}
y
=
\begin{cases}
x & ( x \geqq 0 ) \\
0 & ( x \lt 0 )
\end{cases}
\end{eqnarray} | Relu活性化関数 |
2.Reluの特徴 | |
Reluの特徴
良い点
・xが正のとき活性化関数の微分は常に1になるので、Reluは勾配消失が起きにくい.
シグモイド関数では勾配がゼロになることが多く、勾配消失の問題が多かった
・計算が簡単で高速
問題点
・あるとき常に同じ値をだす問題にはまってしまうことがある
xが負のときに0となって変わらなくなり、あるニューロンがどの入力を受けても常に同じ値を出すことがある。これを回避するために、負のときも少し勾配をもたせたLeakyReluなどが使われることがある. | Reluの特徴 |
この章を学んで新たに学べる
Comments