-
 @ThothChildren
@ThothChildren
- 2024.7.6
- PV 118
Whisper
ー 概要 ー



- 話者は識別できない
- 会話の開始時刻、終了時刻、文字列を出力
- 音声データの会話から文字列を出力
- 言語不明の場合は、言語の推定も指定可能(もちろん言語を指定して使用も可能
- 30秒ごとに認識し文字起こし
- 学習データに英語データが多いため、英語の性能が高く他言語は劣る
- モデルサイズが複数あり、性能が比例
解 説
Whisperのわかりやすい解説動画 | |
1.Whisperの概要 | |
Whisperは68万時間の音声データを元に学習された自動で音声から文字列を出力するAIモデル(深層学習, DeepLearning, Transformerモデル)です。
68万時間のうち、英語が43.8万時間かつ英語翻訳 65%, 非英語が12.6万時間かつ英語翻訳18%,残りが17%が非英語で非英語翻訳となっています。これによって99言語の言語の推定を行えています。
この言語モデルのソースコードは全てGithubで公開されており、また論文で技術の解説も行われています。 | Whisperモデルのわかりやすい解説 |
undefined | 外部リンク OpenAIのWhisperに関する記事 |
undefined | 外部リンク OpenAI/WhisperのGithubリンク |
2.Whipserモデルの内部構造 | |
2.1.Transformerベース | |
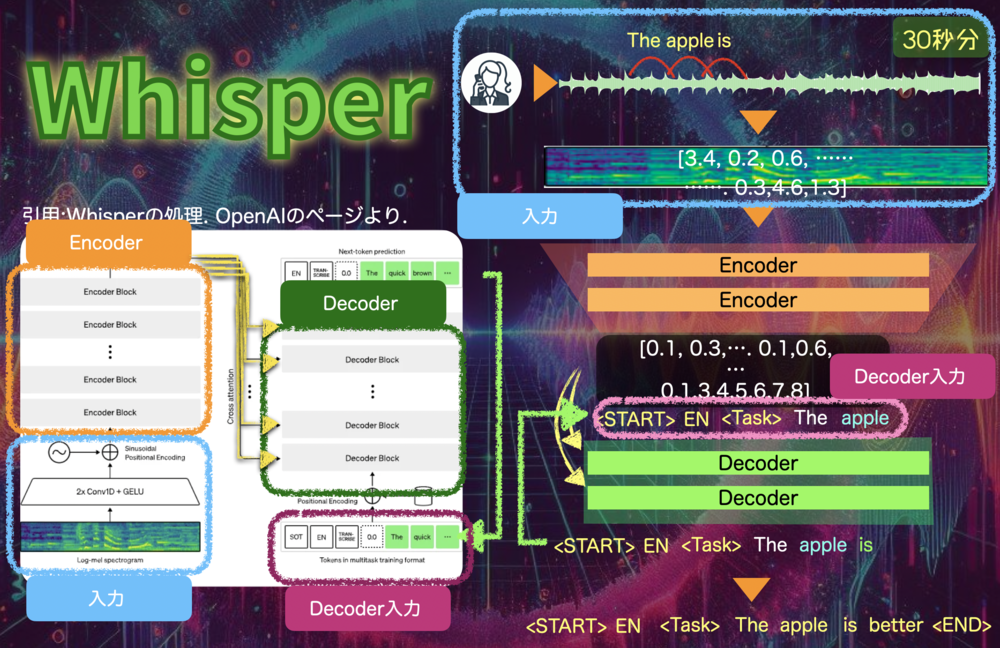
 | Whisperモデルの構造.
上側がEncoder,下側はDecoder.
Encoderの出力をDecoderの各層に注入する形となっている.
Decoderでは、左端の最初の文字列を与えると続きの文字列が一つ得られるため、これを最大224回繰り返して、最終的な文字列を得る。最後には文字列の終端を示すENDの文字列が出てくる。 |
WhisperはTransformerのモデルをほとんど踏襲しています。
Baseモデルの場合は、6層のEcnoderと6層のDecoderを持ちます。
Transformerと異なるのは、Encoderの入力が音声データのため、メルスペクトログラム変換によって人間の耳と同じような特徴の捉え方をする変換を行なっていることです。
全体像を追ってみましょう. | WhisperはTransformerベースなモデル |
2.1.1.前半 : Encoder | |
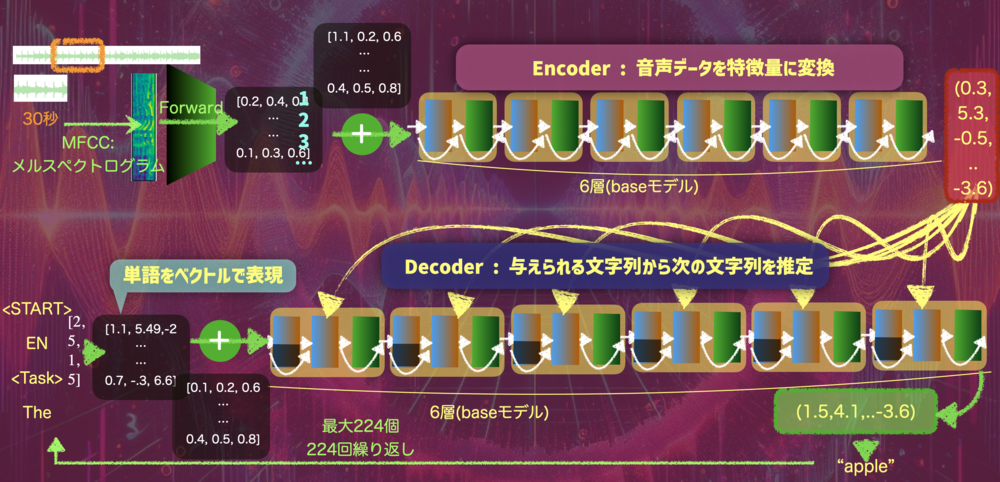
一回分のデータを処理する流れは下記のようになっています。 まずEncoder部分をみてみましょう.
| 一回分(30秒)のWhisperの処理
Encoder部 |
2.1.2.後半 : Decoder | |
では後半部分のdecoderです.
| 1回分のDecode処理(Whipserモデル)
この処理を"EndOfTrascription"が得られるまで繰り返します |
3.各詳細技術解説 | |
それでは、上記の流れの中で出てきた技術がどのようなものか概要を確認していきましょう。 | Whisperモデルで使用される技術詳細 |
3.1.Tokenizer | |
まずはTokenizerが何をしているかから確認します。
Whisperで使用しているTokenizerはGPT2やその他多くの言語で使用されている技術と同じものです. 自然言語処理のモデルでは、文字列を処理することになりますが、まずこれを数値に変換、または単語に変換しなくてはDeepLearningのモデルでは扱うことができません。単語を表すバイト文字列の数値それ自体には意味がないためです.(Aが65だとしてもその数値の大きさに何も意味がない)
Tokenizerは各単語をIDに変換するための辞書のように考えてください.
"今日"→43832
のような変換を持っています。実際にTokenizerに43500~43800の値を出力すると以下のようなリストになっています。 | Tokenizerの役割.実際の処理. |
 | Tokenizerの43500~43800の表現する単語 |
実際に見てみると中身は言語にも依存せず、さまざまな単語で構成されていることがわかります。また文字単体出ないことにも注目です。 全ての文字列はTokenizerで変換しなくてはなりませんが、全ての文字を持っているだけでなく単語も持つようになっています。 文字ごとのTokenizerを作ることも可能です。Character-Level Tokenizerと呼びます。 しかし、このような変換をして得られたIDは単語の意味を全く表しておらず扱いにくいです。モデルは全ての文字列の前後関係も学習して意味をとらえなくてはなりません。そのため文字ごとだけでなく、単語レベルも持っておくことでその単語の意味を簡単に扱えるようになります。 | Tokenizerの役割続き |
 | Tokenizerの処理.
単語ごとに対応するIDを持つ.
しかしこのIDもまだ大きさに意味がなく、単語ごとの関係性もとらえられていない. |
しかし、このTokenizerはどのように作られるのでしょうか? ただ単に全ての単語を持つとなると大量の辞書が必要です。また新しい単語の組み合わせが出るたびにTokenizerに加えないといけなくなりそうです。 Tokenizerでは、最大のサイズを決めてサイズに達するまで頻度の高い単語を得ることを行います。 全ての単語の頻度を計算し、残っているペアで最も頻度が高いデータを辞書(Vocab)に追加します。次はそれらを合体した塊にして、残りの中から頻度が高いものを選択していきます。 | Tokenizerの作り方 |
 | Tokenizerの作り方 |
これまで単語としてきましたが、実際にはByteの組み合わせでTokenizerを作っています。この手法をByte Pair Encoding(BPE)と呼びます. WhisperはUnicodeで言語を表現しています。そのため"今日"は、"0xe4 0xbb 0x8a 0xe6 0x97 0xa5"と表現できます。BPEではこのレベルに分解した上でTokenzerにどの組み合わせが多いかを登録しています。単語レベルではないため、単語の途中で切れてしまう可能性も全然ありますが、先ほどの実例のように大抵は奇妙な別れ方はしていません。 最初単位が1バイトのため、255通りの表現が最初に登録されています。そのあと50000個の頻出単語を追加して、終端単語の表現を持たせているため、50000+255+1 = 50256個のサイズになっています。 単語数は多くてもモデルが大きくなり、小さくなっても学習に時間がかかるため、ちょうど良い大きさにしておく必要があります。 | BPE ( Byte Pair Encoding) |
3.2.Embedding | |
このようにして文字列を単語のIDの配列に変換したら、最後にEmbeddingで、単語の特徴ベクトルに変換します。 これまでのIDの値は大小に意味がなく、単語間にも関係性がありませんでした。 そこでIDと一対一に対応する特徴ベクトルへの変換処理としてEmbeddingを行います。 これによって次の位置エンコーディングやEncoderに与えることができます. | Embedding |
3.3.言語の推定 | |
言語の推定はWhisperモデルをそのまま使用し、Decoderの出力から得られた各単語の可能性のうち、最もスコアが高い単語を選んでいます。
音声データの初めの30秒を使い推定します。 | 言語の推定方法 |
 | 言語の推定. |
3.4.Decoderでの単語の決まり方 | |
 | Decoderの出力後の計算.
各TokenIDごとにスコアが出力される。この時点では足しても1になるようなことはない。
まず、FIlterで空白の除去や文字起こしさり得ない単語の除去、タイムスタンプの表現の制約などで綺麗にして、関係ないものはスコアをマイナス無限大にする。
その後通常のlog_softmaxなどで扱いやすいように変換しておく。 |
出力では、TokenIDに対応するような各単語のスコアの配列が得られlogitsに入れられています。 この中で一部filter処理でヒューリスティックに評価値を調整します。 例えば特定のタイミングの空白を禁止したり、使用できないIDを除去するなどを行います。 そうして整形されたスコアからlogsoftmaxを計算し、logprobに入れます。 計算されたこのlogprobが最大の単語を選べば良いでしょうか? その場合の方法をGreedySearchと呼びます。 しかし、実際にはもっと良い方法が提案されており、WhisperではBeamSearchを適用しています. | logitsとlogprobの計算 |
3.5.BeamSearch | |
 | GreedySearchとBeamSearchの違い.
ついでにTemperatureによる制御も |
BeamSearchではGreedySearchのような最もスコアが高いものを選ぶのではなく、複数の単語の文字列候補を持っておき、次に来るべき単語として最もよいものおよびこれまでのスコアの合計を計算します。 これによって前後の文章の関係も踏まえたよい文字列を得ることができます。 WhisperではBeamSizeを指定することでBeamSearchでの結果を得ることができます。 | BeamSearhの解説 |