| Stable Diffusionのわかりやすい解説動画 |
右リンクに大元の英語のStable Diffusionの解説を添えておきますので参照ください. | |
Stable Diffusionが公開されたことで、一般の方でもコードを手元にクローンして自身のローカルPCで試せるようになりました.
論文もソースコードも公開されているため、どなたでも試すことができます.
簡単な紹介も上記のリンクに英語で記載されていますので、ご参照ください.
今回のStable Diffusionの仕組みを知るには、事前に学ぶべきことが多くなっています.
・VAE : Variational AutoEncoder : 潜在変数から画像、画像から潜在変数を担うAutoEncoder
・ CLIP Text Encoder : ユーザの文字列を適切な特徴量に変換するエンコーダ. 内部ではTransformerやVisual Transformerなどこちらも学ぶ必要がある.
・U-Net : 長く活躍している変換系を担うモデル. 今回はDiffusion Modelのノイズ除去を学習する.
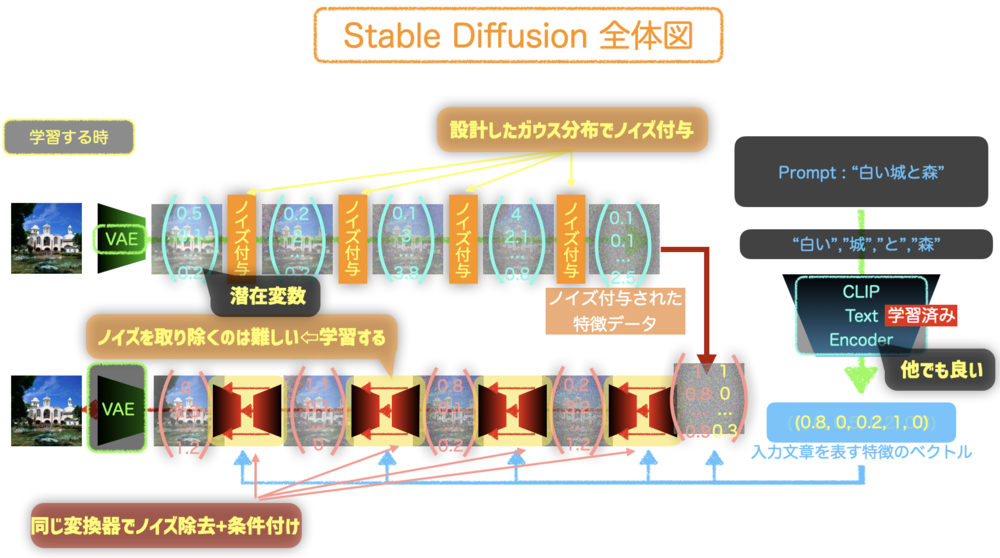
・Diffusion Model : 今回のモデルの中心. 画像へノイズを繰り返しかけて、それに対して繰り返しノイズ除去を行うモデルを学習する. Stable Diffusionでは潜在変数を学習することがポイント.
・Cross Attention : ユーザの入力データの特徴量を使って、Diffusion Modelの生成を誘導するために必要.
のような主要技術を抑えなくてはなりません. | 前提 |
1.Diffusion Model | |
| Diffusion Modelの概要 |
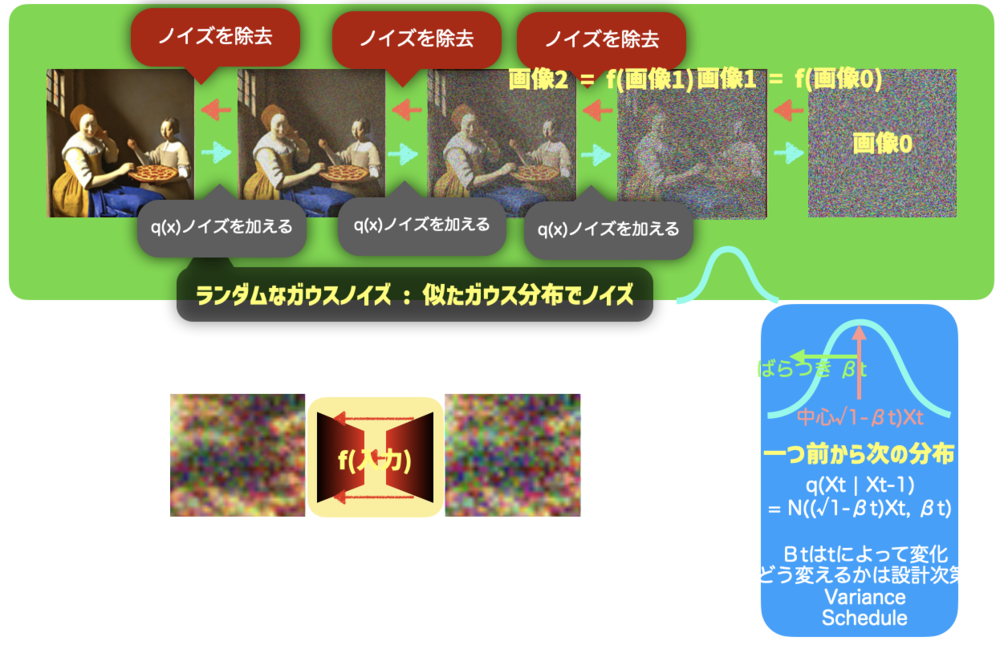
Diffusion Modelでは、ノイズを加えるq(x)の処理とそれを除去するp(x)の処理があります. q(x)はガウス分布とその設計したパラメータによって既に関数は定まっていますが、p(x)がわからないため、学習を通してそれを学んでいくことになります.
p(x)の一度の除去は少しずつになります.50~100回ほど処理することでノイズから綺麗な画像へと変換されていきます.
実際に上の図のように一つの画像からノイズ除去をするのはクローズアップすると難しいことがわかります.これを学習しなくてはなりません. | Diffusion Model概要 |
2.U-Net | |
| U-Net概要 |
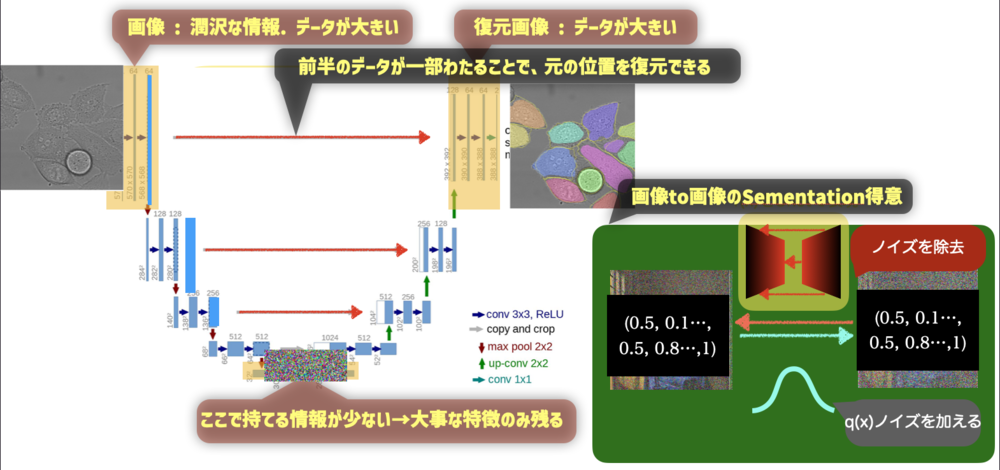
Stable Diffusionでは一度の変換をU-Netで学習していきます.
U-Netは、画像から画像への変換を得意とします.
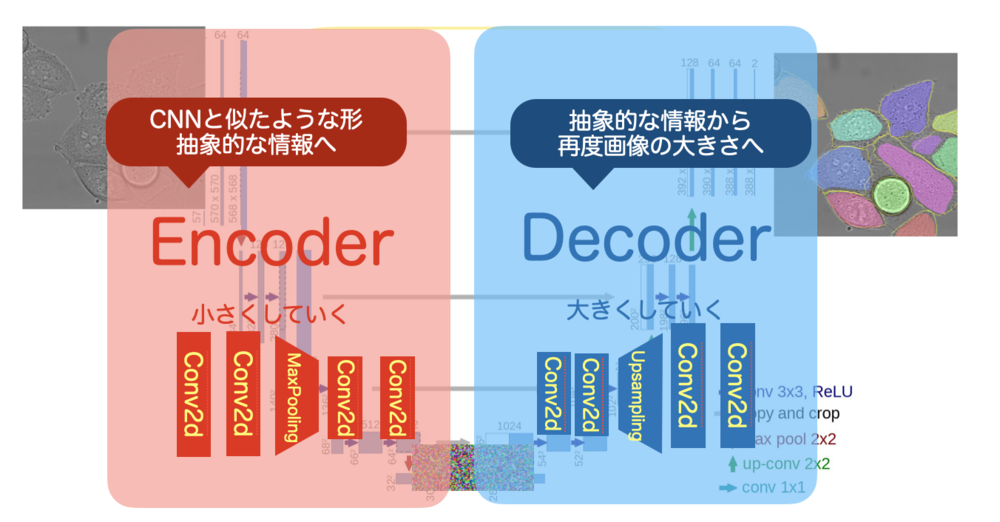
通常は画像などを入力として次第にConvolutionやMaxPoolingなどで解像度を下げて情報を抽出します. 最も情報が少なくなったところから再度画像を拡大していきます. AutoEncoderのように中心部分で情報が抽出されます.
最後解像度の高い画像を生成するために、前半部分の情報を受け渡しているのがわかります. これがU-Netの特徴で一度失われる画像上での情報を再度後半に渡すことで適切な位置にマッピングすrことをかのうにしています. | U-Netの特徴 |
| U-NetのEncoder部分とDecoder部分 |
3.Cross Attention | |
| Cross Attentionの組み込まれ方 |
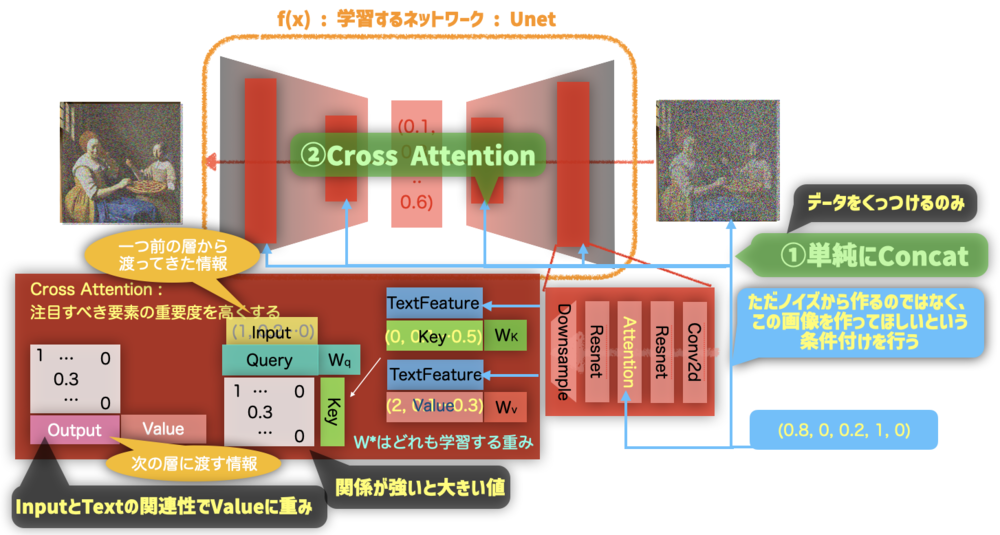
ユーザからの入力をDiffusionModelに繋ぎ込むために二つの方法をStableDiffusionでは用意しています.
一つは、入力にConcatする方法です. これは単純にベクトルを足し合わせるのみです
.
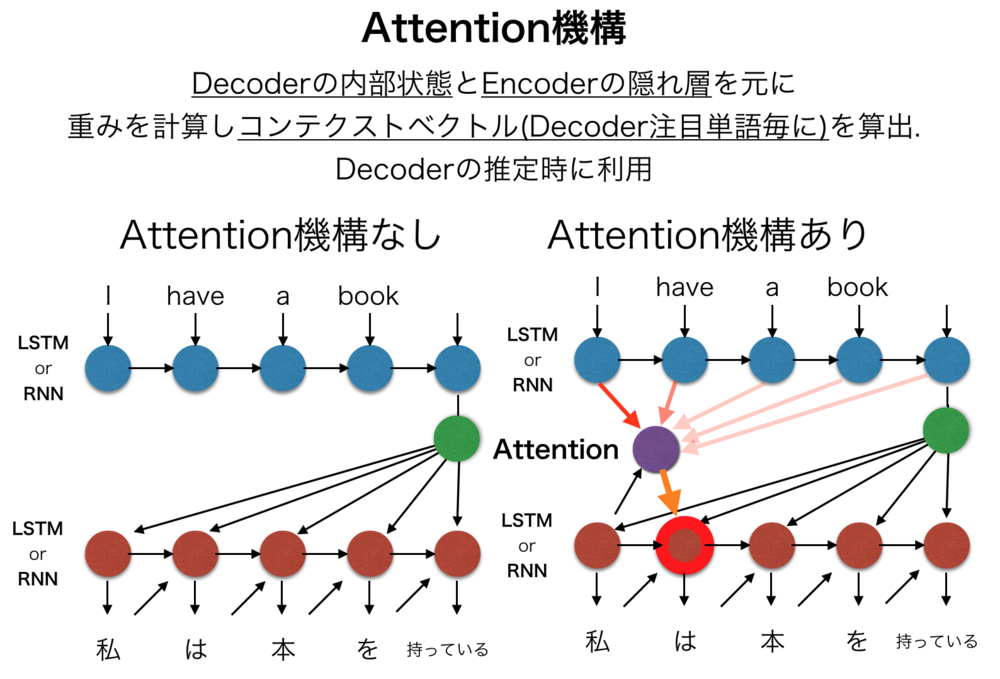
もうひとつがここで紹介するCross Attentionです. これはよく話題となるAttentionそのものです. このCross Attentionを先ほどのU-Netの随所に挿入することで条件付きU-Netを実現しています.
Attentionは簡単に紹介すると、QueryとKeyの関連性で重みを計算し、その重みをValueにかけることで重要な内容をより扱うように再調整する仕組みです.
今回はユーザの入力をKeyとValueへ入れています. | Cross Attentionの使われ方 |
Attention機構へは右から | |
4.CLIP Text Encoder | |
| CLIP Text Encoder概要 |
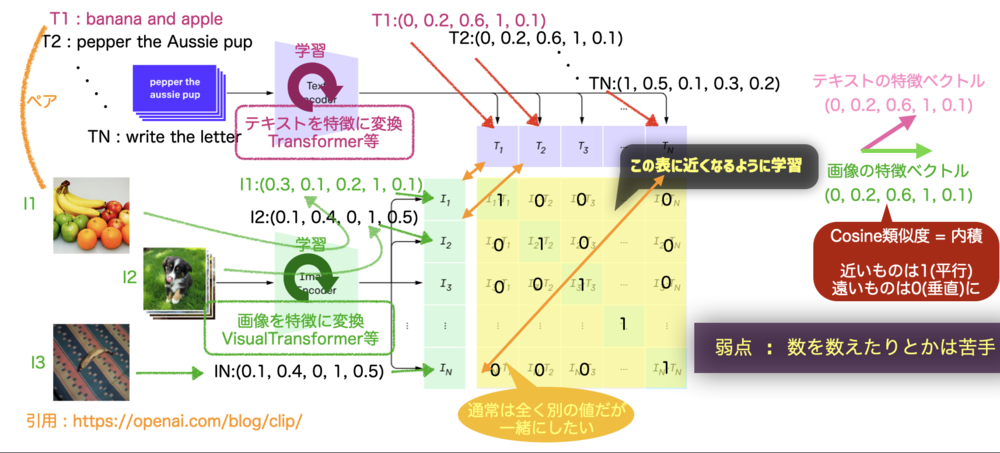
CLIP Text EncoderはOpenAIが発表したモデル.
テキストとテキストに対応する画像の特徴量を近づけるように各ベクトルの内積を同じなら1、異なるなら0に近づけて学習させている.
各データを変換するTransformerを学習させている.
Imagenなどと同様にStable Diffusionはこの学習済みモデル流用しているだけで、Diffusion Model学習時に一緒に学習などは行なっていない. | CLIP Text Encoder |
5.VAE | |
| VAEの概要 |
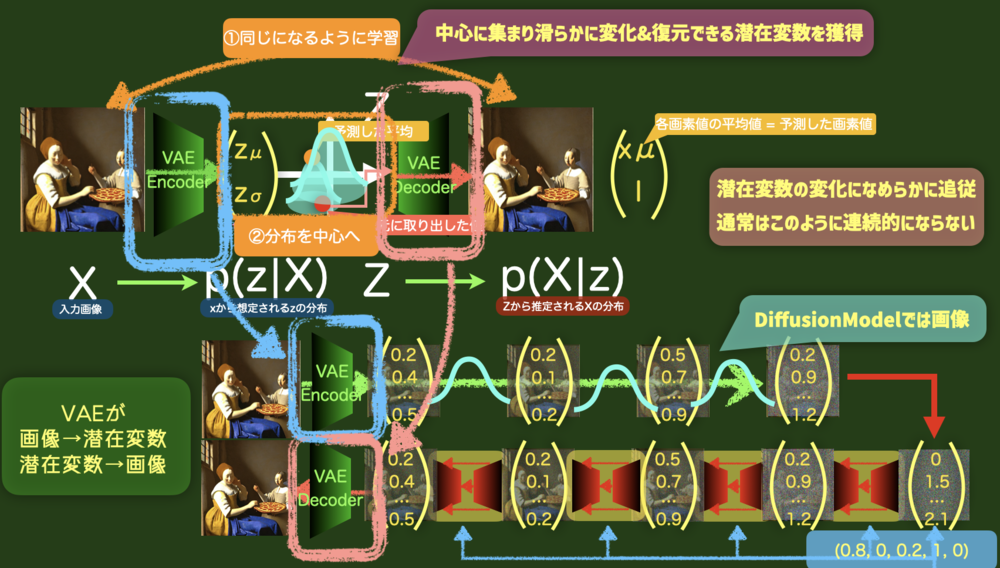
今回のポイントである潜在変数と画像の変換部分を担う役割.
VAE自体は、データの分布を推定するためのモデルで、事前分布及び事後分布を予測することでそのデータの分布を推定する.
アプリケーションとして潜在変数の変化に沿って滑らかな出力画像の変化が得られるのが特徴.
VAEでは制約二つを課すことがポイントとなっており、
一つは入力画像と出力画像が一致すること、
二つ目は、分布が平均0分散1のガウス分布になること
がある. | VAE役割. |
 @ThothChildren
@ThothChildren