-
 @ThothChildren
@ThothChildren
- 2020.8.29
- PV 392
DBSCAN
ー 概要 ー
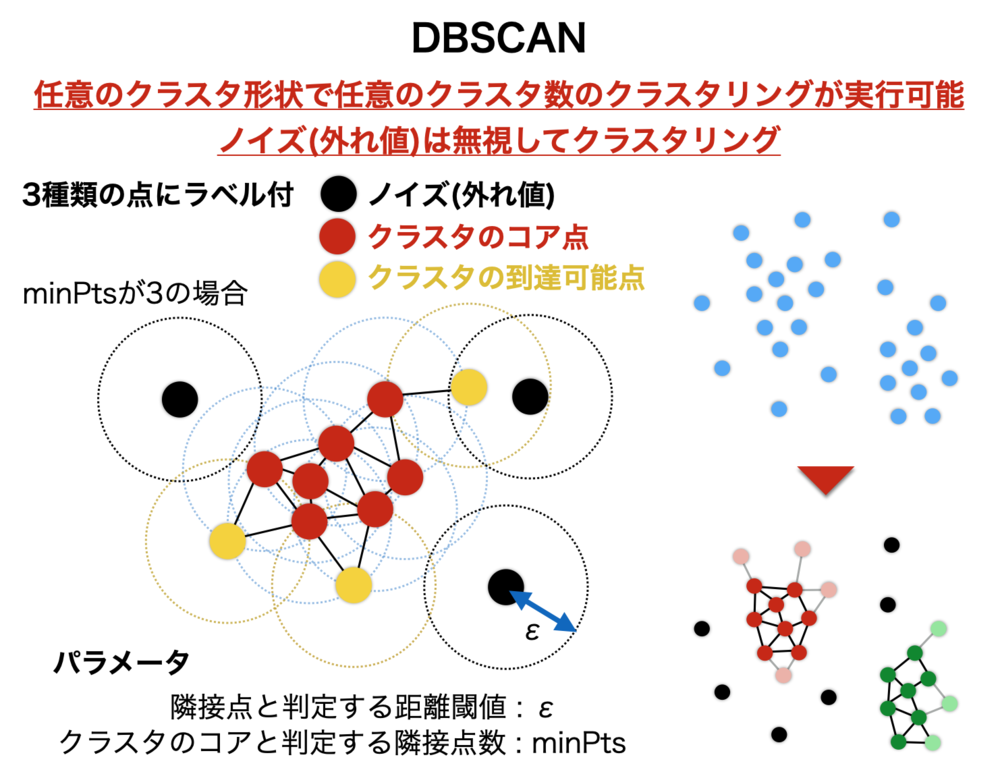
DBSCAN(Density-based spatial clustering of applications with noise)は主に密度の高い箇所と低い箇所の違いでどんなクラス数でどんな形状でもクラスタリング可能な手法. k-meansと違い予めクラスタ数は不要で線形分離できないクラスタリングも可能.



この章を学ぶ前に必要な知識
条件
- クラスタと判定される隣接点数minPtsを決めとく
- 近い(到達可能)と判定される距離の閾値を決めとく
効果
- 外れ値をノイズとして無視したクラスタリング
- クラスタの形によらず検出可能
- 閾値距離以内に指定数以上の隣接点があればクラスタのコア点
- 閾値距離以内に指定数未満のコア点ならreachable(到達可能点)
- 閾値距離以内にコア点がなければ外れ値(Outlier)
- 密度の高いところをクラスタとし、密度の低いところはノイズとして無視
ポイント
- クラスタ数は勝手に決まる
- クラスタの密度にばらつきがあると適切なクラスタリングができない
- データセットにノイズが入っていても外れ値として無視
- データの順番によって結果が変わる
解 説
わかりやすいDBSCANのアルゴリズム解説 | |
DBSCANはラベルのついていないデータ点に対してクラスタ数を指定することなくクラスタリングすることが可能な手法. 各クラスタ以外にノイズが含まれるデータセットでもノイズ(外れ値)を無視した上でクラスタリングが可能
DBSCAN処理の概要
全てのデータを「ノイズ」か「クラスタのコア」か「クラスタの到達可能点」のどれかに分類し、各点のクラスタを決定する.
パラメータ
予め必要なパラメータは二つのみ
・クラスタのコアと判定する最低隣接点数:minPts
・隣接点と判定する距離閾値: ε
これらを使い
「コア点」: 距離閾値以内の点の数が最低隣接点数を満たす点
「到達可能点」: コア点から距離閾値以内にあるが、最低隣接点数が満たない点
「ノイズ」: 距離閾値以内にコア点が存在しない点
と決める
メリット
・クラスタ数は自動的に決まるため、予め決めておく必要がない(kmeansの場合は必要)
・どのような形状のクラスタでも密になっていればクラスタリング可能
デメリット
・距離算出方法によるが、一般的なユークリッドでは、次元の呪いにより高次元ではうまくクラスタリングできない
・密度が異なるクラスタがあると適切にクラスタリングできない. | DBSCANの概要 |
1.DBSCANの処理 | |
どのような二点間の距離計算を行っても良いが、ここではユークリッド算出であるとする.
DBSCANの処理の流れ
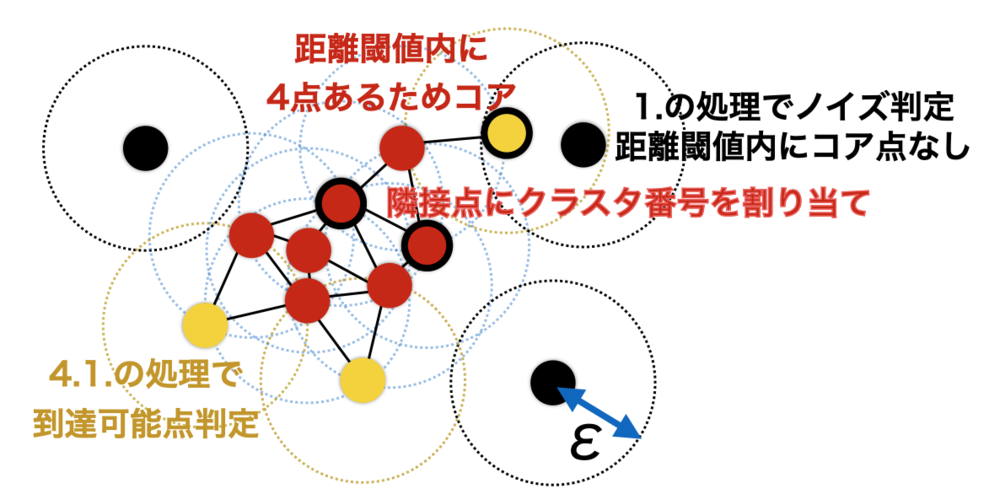
全ての点に関して下記処理を行う.
1. 対象の点Pの距離閾値εの隣接点数がminPts以下なら
→一旦ノイズとラベル付して、次の点の処理へ.
そうでない場合は2.へ
2. 点Pにこれまでつけていないクラスタ番号を割り当てる
3. 点PのクラスタリストNeighborListに隣接点を加える
4. 以下NeighborListの各点Qに対して
4.1 Qがノイズの点があればPに割り当てたクラスタ番号を割り当て
4.2 Qが既にクラスタが割り当たっていれば、次の点の処理に4.1へ
4.3 QにPのクラスタ番号を割り当て
4.4 もしQの距離閾値εの隣接点数がminPts以上ならそれら隣接点をNeighborListに追加
1.の処理で密度が十分にあるかを判定している. これによってコア点になりうるかどうかが決まる. 密度が足りないものは一度ノイズと分類し、コア点から距離閾値以内にあれば、到達可能点として復活する.
4.2.の処理でわかるように、既に割り当たっているものにはラベルを付け替えないため、このDBSCANは走査するデータ点の順序によってクラスタリング結果は異なる. | DBSCANの処理概要 |
 | DBSCANの処理のイメージ |
この章を学んで新たに学べる
Comments