-
 @ThothChildren
@ThothChildren
- 2018.12.1
- PV 230
Neural Gas
ー 概要 ー
Neural Gasは元々の多数の入力ベクトルデータを少数の特徴的なベクトルを用いて代用するベクトル量子化に利用されるニューラルネットワーク.
Neural Gasはよく自己組織化マップ(SOM)と比較されるが、自己組織化マップは学習時に隣接ベクトルとの制約があるのに対してNeural Gasはそれを持たない.
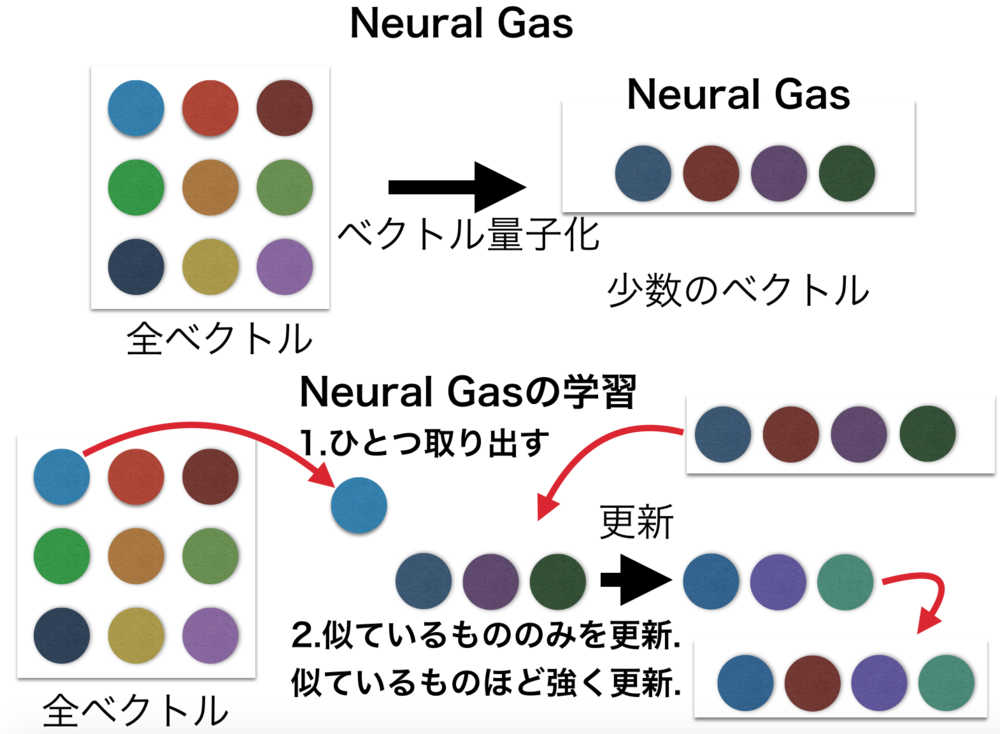



この章を学ぶ前に必要な知識
条件
- 入力は多数のベクトル
- 出力の次元数を決めておく
効果
- 与えられたデータに合わせてベクトル量子化を行う
- データ圧縮、ベクトル量子化などを行い、画像処理、クラスタ分析、パターン認識に用いられる
ポイント
- 繰り返し誤差の反映を計算することで学習を進める
- 誤差の反映はデータ一つにつき一度行うオンライン学習と複数のデータの誤差をまとめて反映するバッチ学習がある
- 自己組織化マップ(SOM)では隣接の制約があったが、Neural Gasにはない
- クラスタ分析においては、k-meansが一つのデータを必ず一つのクラスで考慮するのに対して、Neural Gasは一つのデータを複数のクラスで考慮する
解 説
Neural Gasは元々の多数の入力ベクトルデータを少数の特徴的なベクトルを用いて代用するベクトル量子化に利用されるニューラルネットワーク.
データ圧縮、ベクトル量子化などに利用できるために、画像処理、クラスタ分析、パターン認識など幅広い分野に用いられる.
他技術との比較
Neural Gasはよく自己組織化マップ(SOM)と比較されるが、自己組織化マップは学習時に隣接ベクトルとの制約があるのに対してNeural Gasはそのような制約を持たない.
Neural Gasはクラスタ分析を行うk-meansとも比較される.
k-meansはデータを扱う時に一つのデータは一つのクラスにしか考慮されないが、
Neural Gasは複数のクラスにおいて考慮されて更新が行われる.
k-meansを一般化したものがNeural Gasである. | Neural Gasとは |
1.Neural Gasの学習 | |
| Neural Gasの学習過程概要 |
Neural Gasの学習アルゴリズムは非常に簡単.
学習アルゴリズム
0. Neural Gasのノードの数(次元数)を決めて、入力と同じ次元数のベクトルを各ノードに一つずつ持たせる.それらはランダムに初期化しておく.
1. データを一つ取り出す.
2. Neural Gasのノード全てを1.で取り出したデータと以下の式を使って更新.\(\epsilon\)は学習係数, \(\lambda\)は隣接距離.式の解釈はあとで説明.\(k\)は何番目に似ているか.
$$w_{t+1} = w_{t} + \epsilon e^{-\frac{k}{\lambda}}(x-w_t)$$
3. 更新量が一定以下になったら学習を完了. | Neural Gasの学習アルゴリズム |
上記の更新式の解釈は非常に簡単.
\(w_t\)はある時間tにおける特徴ベクトルを表しているが、これを与えられたデータ\(x\)との誤差を元に\(w_{t+1}\)に更新する.
もし\(x-w_t\)の係数が1なら(k = 0つまり最も似ているもの, \(\epsilon\)が1のとき)
$$w_{t+1} = w_t + x - w_t = x $$
となる.
つまり、この更新式は\(w_t\)をどれだけ\(x\)に近づけるかの更新をしているにすぎない.
係数に関しては、あまりにもどれかのベクトルに近くなるように更新していたら新しいデータが来るたびにそのデータにすごく近くなってしまっていつまでも更新が終わらない.それを調整するのが\(\epsilon\)の役割.
更新する量を\((x-w_t)\)から小さくしてやることで、ちょっと入力データ\(x\)に似せるように更新を行えるようにする.
さて次に\(e^{-\frac{k}{\lambda}}\)はすでに似ているNeural Gasの特徴ベクトルだけ更新してあげる縛り.
全ての特徴ベクトルを更新してしまっていてはこれもまた更新がいつまでも終わらない.
あくまで似ているものに重みをつけて、より似るように更新を行う.
あらかじめ全特徴ベクトルが入力データ\(x\)と似ているかを求めておき何番目に似ているかを\(k\)として持っておく必要がある.
kが大きくなると\(e^{-\frac{k}{\lambda}}\)は小さくなっていくため、更新する量も減っていく. | 上記アルゴリズムの更新式について |
自己組織化マップでも同様なことがあったが、
学習の方法には大きくオンライン学習とバッチ学習がある.
オンライン学習は上記のアルゴリズム解説のように一つのデータを取り出して更新するが、これでは順番に大きく左右されて更新がされてしまう.一つのデータによって大きくずれてしまうこともある.
そこで、バッチ学習は複数のデータを取り出してその差分を使って一気に更新を行っている.
| オンライン学習とバッチ学習 |
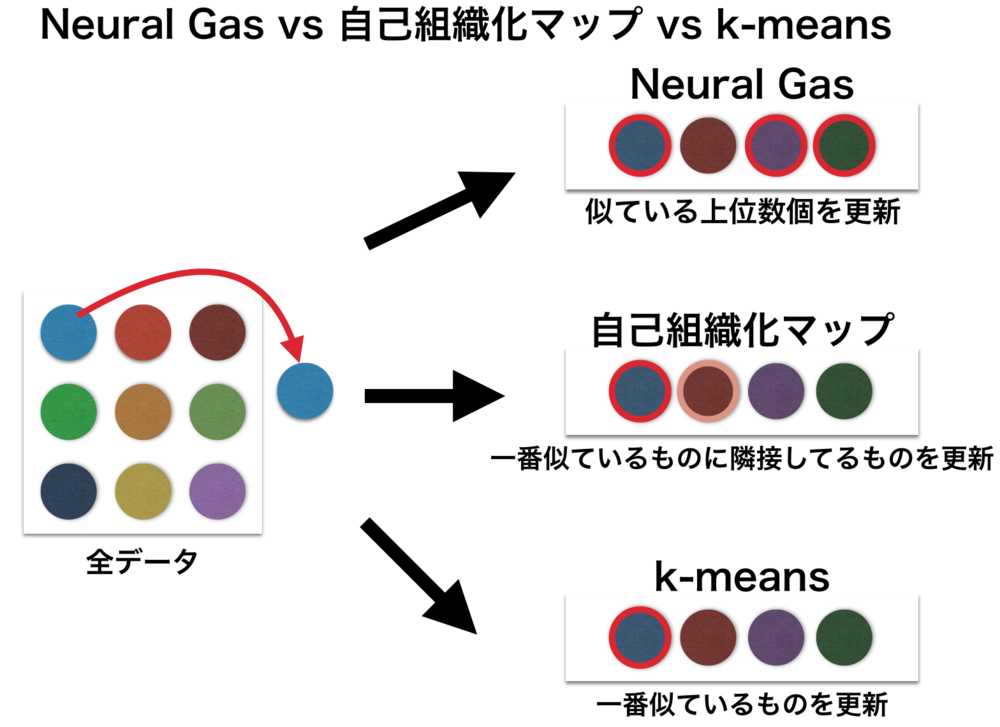 | Neural Gas vs 自己組織化マップ vs k-means
Neural Gasと自己組織化マップは最終的に更新するものは最も似ているものだけになる.
最初の間は広範囲に更新を行う. |
この章を学んで新たに学べる
Comments