-
 @ThothChildren
@ThothChildren
- 2018.10.21
- PV 383
複数枚を補間して動画をスローにしたい
ー 概要 ー
動画から取り出した連続する2枚のフレーム画像の間を補間する方法についてまとめています.ここではNVidiaが提案したEnd to EndなCNNによるSuper Slomoについて紹介します.



この章を学ぶ前に必要な知識
条件
- 動画が入力
効果
- 各フレーム間を補間する画像を生成する
ポイント
- ここではNVidiaのSuper Slomoについて紹介
- 深層学習(Deep Learinig)ベースの手法
- この手法では、時間に依存するパラメータを持たないので自由に補間枚数を決められる
解 説
動画から取り出した連続する2枚のフレーム画像の間を補間する方法についてまとめています.
ここではNVidiaが提案したEnd to EndなCNN(Deep Learningの技術の一種)によるSuper Slomoについて紹介します. | 複数枚を補間して動画をスローにする方法について |
1.NVidiaのSuper Slomo | |
NvidiaのSuperSlomoの動画を以下にリンクします | NVidiaのSuper Slomoについて |
NVidiaのSuper Slomoのデモ動画 | |
NVidiaのSuper Slomoの論文をリンクしておきます. | 外部リンク Super Slomoの元論文 |
1.1.Super Slomoの技術解説 | |
SuperSlomoの概要について記します.
SuperSlomoはDeepLearningにおいて頻出であるCNN, Unetを用いた深層学習による動画補間の手法です.
簡単な流れ
0~1秒のフレームを補間したいとして補間するフレーム時間をtとする.
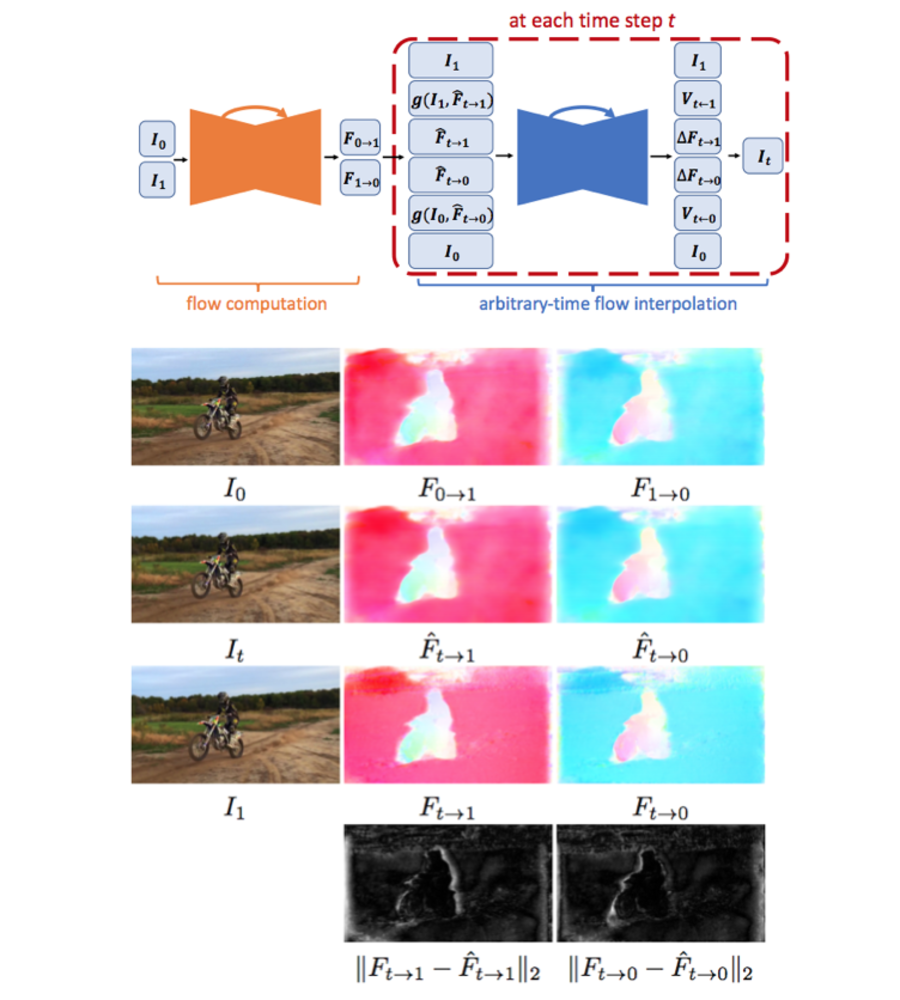
①動画内の二枚の連続する画像(A,B)を元に、どのようなオプティカルフローがあったかを推定(CNN, Unetによる).このときF(A→B)とF(B→A)の両方を推定.
② また、見えるか見えないかのVisibilityMap V(A→t), V(B→t)を推定
③ Flowの推定 + 入力画像 + VMapを使って補間画像 I を推定 | SuperSlomoの概要 |
| SuperSlomoの論文より引用.
上段は、ネットワーク全体.(ネットワークは二段階)
下段は、FlowのFを表示している. |
それではSlomoの詳細について説明.
登場する情報
・\(I_0,I_1\) : 入力画像. 時間0での画像と、時間1での画像
・\(I_t\) : 補間した出力画像.
・\(F(0→1), F(1→0)\) : それぞれの画像からみてどのように動いたかのOpticalFlow
・\(F(0→t), F(1→t)\) : 補間時間tまでのそれぞれの画像からの仮推定OpticalFlow.
・\(\widehat {F(0→t)}, \widehat {F(1→t)}\) : 補間時間tまでのよりよく推定したOpticalFlow.
・\(V(0→t), V(1→t)\) : 補間時間tでの見える部分の変化領域.オクリュージョンを推定.
登場するネットワーク(CNN)
全部で使うネットワークは3つ.どれもCNNで構成.
①\(F(0→1), F(1→0)\)を推定するネットワーク : Unetを用いて、入力画像間\(I_0, I_1\)の補間を行う.
②\(\widehat {F(0→t)}, \widehat {F(1→t)}\) を推定するネットワーク: 境界線など動きが滑らかでないところでは、仮で推定した\(F(0→t), F(1→t)\)では精度が出ない.主に境界線周りでこれを修正するようにする.
③\(V(0→t), V(1→t)\)をステイするネットワーク: 入力画像からどこが可視されている部分かオクリュージョンかを推定するネットワーク
他は全て通常の計算で算出
上記のネットワークで出したもの以外は、通常の計算で求める.
具体的には、\(F(0→t), F(1→t)\), \(I_t\) などは計算で求めている.
| Slomoの詳細 |
SuperSlomoはUnetを使用していることはすでに述べた通り.
OpticalFlow推定のネットワーク工夫
入力に近いConvolution層ではできる限り大きなOpticalFlowも捉えられるように7x7のサイズのフィルタを設定.数段めからは5x5や3x3になるようにしている.
また、poolingはAveragePoolingを用いている.
| Super SlomoにおけるCNNのポイント |
この章を学んで新たに学べる
Comments