-
 @ThothChildren
@ThothChildren
- 2018.9.16
- PV 274
FCN (Semantic Segmentation)
ー 概要 ー
FCN(Fully Convolutional Networks for Semantic Segmentation)は、FCNのネットワーク構造を用いてSemantic Segmentation(領域のクラス分類)を行っているネットワークです.ピクセルレベルでなんの物体なのかを推定します.全結合層を含まないためどのような大きさの画像に対しても適用できるのが特徴ですが、解像度が低くなりがちでまた境界あたりは分類の精度が低く曖昧になりがちです.



この章を学ぶ前に必要な知識
条件
- 任意のサイズの画像が入力
効果
- ピクセルごとにクラス分類が可能で、画像の各領域を分類できる
ポイント
- ネットワークの過程で小さくしていくため、結果は解像度が悪くなりやすい
- 解像度が低いため領域の境界が曖昧になりやすい
- Convolution層とPooling層のみで構成され、全結合層は含まない
- RCNNの系列のような領域候補の提案は行わない
解 説
本論文のリンクを貼っておきます. | 外部リンク 元論文 |
FCN(Fully Convolutional Networks for Semantic Segmentation)は、FCNのネットワーク構造を用いてSemantic Segmentation(領域のクラス分類)を行っているネットワークです.
Segmentationとは画像の領域を分割することですが、Semantic Segmentationは何が写っているかで画像を分割するタスクです.犬の部分は全部赤色、空は全部青色、草は全部紫色のように塗り分けます.
ピクセル単位で何の物体なのかを推定します.((x,y)=(120, 150)の画素は、"犬"といった形で推定)
全結合層を含まないためどのようなサイズの画像に対しても適用できるのが特徴ですが、解像度が低くなりがちでまた境界あたりは分類の精度が低く曖昧になりがちです. | FCN(Semantic Segmentation)とは |
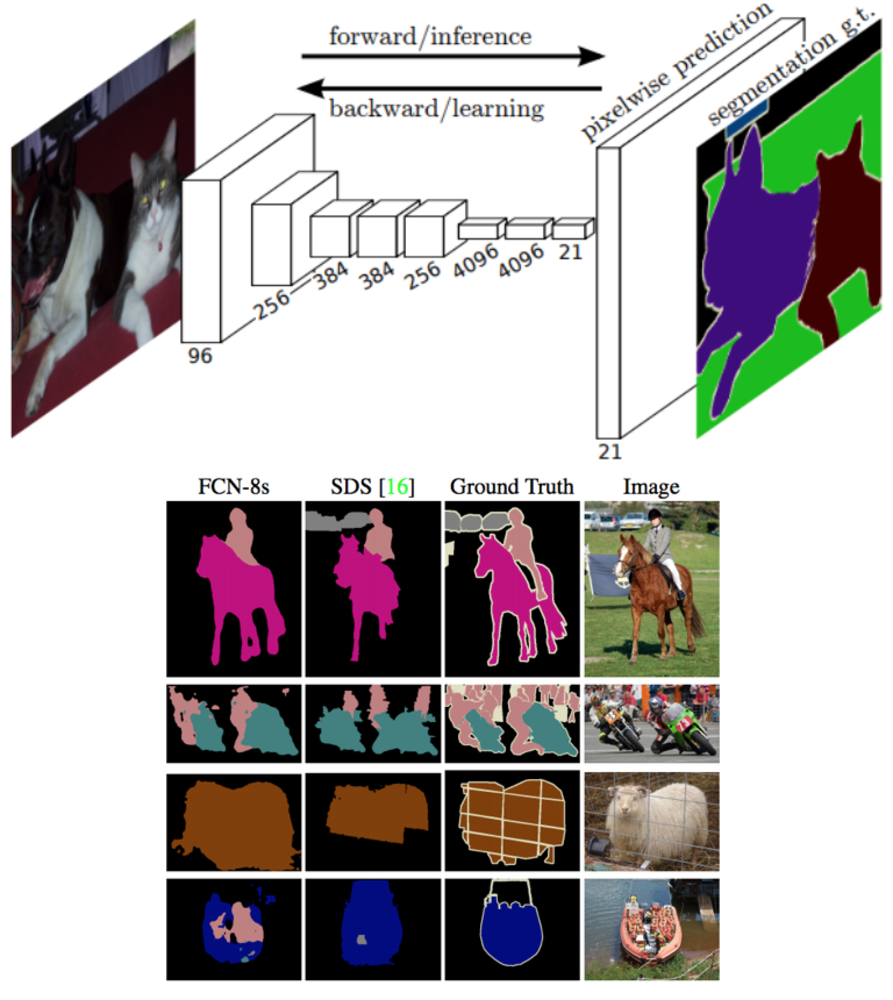
| 論文より引用.
全てのレイヤでConvolution層とPooling層が作られます.
各クラスを推定するEncoder部分と各クラスを領域分割して作成するDecoder部分(この図には図示されていません)があります.
下側の図が結果になります.
右端の列が入力画像で、左端の列が提案手法の分類結果になります.右端から二列目が正解の領域です. |
上の図の最後の絵のように、領域を推定するにあたって、画像の領域に対して小さすぎる部分等はあまり精度がでないのも特徴です. | FCNに関して |
FCN前半のサイズを小さくしていくEncoder部分によって各領域の分類が完了したが、これをできる限り入力と同じぐらいの解像度に復元するDecoder部分が必要となる.
FCNにおいては、これはUpsamplingをするDeconvolution層とEncoderの一部の特徴量マップ(次元圧縮したもの)を足し合わせることでDecoderを実現していた.
このDecoder部分においては、最後のDeconvolution層を除いて学習するようにして(初期化時はbilinear upsamplingの係数)、最後の層のみbilinear upsamplingを行うパラメータに固定していた. | FCNのDecoder部分に関して |
この章を学んで新たに学べる
Comments