-
 @ThothChildren
@ThothChildren
- 2018.5.23
- PV 250
フィルタで偽陽許して含むか判定したい
ー 概要 ー
配列を持つフィルタを使って、含むかどうかの判定に関して含まない場合は絶対に間違えず含む場合には含むかもと判定することができる技術について紹介します.データが大量にある場合にメモリ空間を節約しつつまた高速に含むかどうかを判定することができます.これらフィルタは含むと答えた場合は間違えていることもあるのが特徴です.



この章を学ぶ前に必要な知識
条件
- 入力によってまちまちな値を返すハッシュ関数
- ハッシュデータを保存する長さkの配列
効果
- 高速にメモリを使用せずに特定のデータが含まれるかどうかを判定
ポイント
- 含まれない場合は絶対に含まれません
- 含まれると判定した場合は、含まれない可能性も含まれる可能性もあります
- ハッシュするデータの数が多くなるほど偽陽性になる確率は高くなります
解 説
特殊なデータ構造を持つことで、データがあるデータの集合に含まれるかをどうかを効率よく判定する技術について紹介します.
フィルタと呼ばれるデータ構造を用いることで、高速にそしてメモリを贅沢に消費することなく判定することができます.
データベース、ファイルシステムなどでよく用いられ、Google BitTable, ApacheHBase, Apache CassndraやLevelDB等において使用されています.
ここで紹介するのは、以下の4つです.
<手法>
・Bloom Filter(ブルームフィルタ)
データの新規挿入とハッシュデータの照合が可能でどちらもO(k).フラグを格納する長さkの配列を持つ.
・Counting Filter(カウンティングフィルタ)
Bloom Filterに削除を含めたもの.ブルームフィルタでは常に配列に1を立てていたが、インクリメントするように変更.削除するとデクリメント.
・Quotient Filter
こちらも削除ができるフィルタで、各配列でis_occupied, is_continuation, is_shiftedを持つのが特徴. ブルームフィルタよりメモリを使うがCounting Filterよりは省メモリ.また二つ以上のQuotient Filterはマージができるのも特徴
・Cuckoo Filter(カッコウフィルタ)
削除操作が可能。ブルームフィルタより必要なハッシュもメモリアクセスも一般的に少ないため高速.
| フィルタで偽陽許して含むか判定したい |
1.Bloom Filter | |
ポイントをすぐに理解できるわかりやすいBloomFilterの解説動画 | |
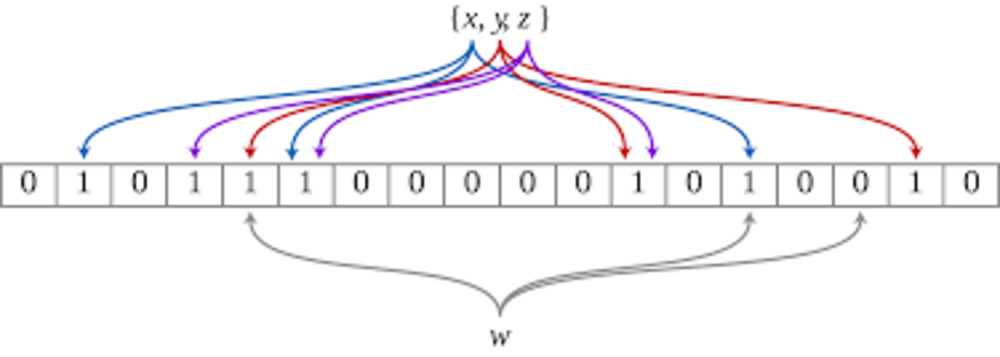
ブルームフィルタの手順はとてもシンプルです.
手順
1. データ群とは別にkの長さの配列を用意します.0で配列を初期化します.
データの登録時
2. 登録するデータを複数のハッシュ関数でハッシュ化して対応している箇所の配列の要素の値を1にします.
データの判定時
3. 探すデータを複数のハッシュ関数でハッシュ化して対応した箇所の配列の要素が全てが1になっていることを確認します.
全て1になっている⇒「含まれている可能性あり」、一つでも1になっていない⇒「含まれていることはない」
| BloomFilterとは |
 | a1とa2を登録しているときに、bを判定している様子です.
この場合偶然bの該当bitが全て経っており、偽陽性を示しています.(bは登録していないので) |
2.Counting Filter | |
Counting FilterとはBloom Filterの配列の各要素において1を立てるのではなく、登録のたびに1を足していく方針に変えた手法.
このようにすることで、削除を行うことができ削除操作の度に1を引くようにすることで実現することが可能になる.ただ1を足していくときにオーバーフローしないように注意する必要がある. | Counting Filterとは |
 | Counting Filterのイメージ図 |
3.Quotient Filter | |
詳しく紹介はしないので、右のWikipediaのリンクで詳細は確認願います. | 外部リンク Quotient Filter(Eng) |
Quotient FilterはCounting Filterよりもメモリ効率をよくしたBloom Filterの改良になります.
Quotient Filterではハッシュがかぶったときの工夫が含まれており、is_occupied, is_continuation, is_shiftedの3つのフラグが各配列において保持されていることも特徴的です. | Quotient Filterとは |
 | QuotientFilterの概念図 |
4.Cuckoo Filter | |
カッコウフィルタはカッコウハッシュテーブルを用いたフィルタです.
二つの配列と二つのハッシュ関数を用意してこのフィルタ処理を行います.
またフィルタのFingerPrintとしてデータの最初の方の数bitも保持しておきます.
<データの登録手順> (結構やっていることはシンプル)
1. データを一つ目のハッシュ関数で一つ目の配列で入れる要素の箇所を決める.もし何もなかったらそこにデータの先頭数bitにあたるFingerPrintを入れて登録終了
.
2. もし1.でかぶっていたら、二つ目のハッシュ関数で二つ目の配列で入れる要素の箇所を決める.もし何もなかったらそこにデータの先頭数bitにあたるFingerPrintを入れて登録終了.
3. もし2.で既にデータが入っていたら、入っているデータを追い出してそこに2.でハッシュ関数を通してデータのFingerPrintを登録. 追い出されたデータは入っていた配列とは別の配列に別のハッシュ関数で該当する要素の入れに行く.もし入っていたら今度は入っている要素を追い出す.
4. 3.を追い出しがなくなるまでまたは操作が上限回数まで行われたら終了する.
こうすることでデータの登録は終わる.
<データの判定手順>
データを二つのハッシュ関数に通してどちらかの配列に自身のFingerPrintと一致するものがあれば「存在する可能性がある」と判定される.データのFingerPrintがなければ存在しない。
偽陽性になるときは、FingerPrintの先頭数bitをどれほどの長さにするかまたハッシュの配列がどれほど長いかによる.
FingerPrintによる一致の確認を行っていることもあり、BloomFilterよりは偽陽性の確率が低い. | カッコウフィルタとは(Cuckoo Filter) |
この章を学んで新たに学べる
Comments