- @aramitama
- 2018.1.15
- PV 151
画像内の単体一般物体のクラスを認識
ー 概要 ー
画像内に映る単体の物体に関してどの物体であるかのクラスを推定します。処理速度が遅いものから速いものまで存在します。



この章を学ぶ前に必要な知識
条件
- 画像を入力とする
効果
- 画像に写っている物体を認識
ポイント
- 近年計算機の能力向上によって実現が可能になってきた
解 説
DeepLearningを境に大きな精度の向上及び技術の転換があったため、
以下では従来の画像処理とDeepLearningの章に分けてそれぞれでの技術に関して
まとめる。
技術の評価ポイントとしては、速度や精度等がある。 | 導入 |
従来の画像処理による一般物体認識の全体の方針の大まかな歴史は、
1.画像全体を使った特徴量を求めて判別(大域特徴量の利用)
2.画像の細かい部分画像を使って特徴量を求めて判別(局所特徴量の利用)
==== 2012年 ======
3.画像全体から自動で特徴量を抽出し判別(DeepLearning)
| 一般物体認識の歴史 |
1.従来の画像処理による一般物体認識 | |
従来の画像処理では、全体の処理の流れが決まっていた。
1.特徴量抽出
2.学習器で判別
と大きく二つの段階を経て物体の識別を行う。 | 従来の画像処理導入 |
特徴量算出では様々な特徴量が提案された。
最古のものではWaveletがあげられる
特徴量として代表的なものはSIFT, SURF, HOG, Haar-liikeなどがあげられる。
SIFTは遅いが精度がよく、SURFはそれを高速した特徴量。
HOGは画像の輝度勾配に基づいて算出される特徴量。
タスクによって上記の特徴量を使い分けて特徴抽出を行う。
| 1.特徴量抽出に関して |
学習器による判別では、Bags of Visual Wordsという手法が最も有名です。
局所的な特徴量を画像の各部位で算出し、あらかじめ決められている局所特徴量のどれと似ているかでヒストグラムを作成しそれを画像全体の特徴量とする手法です。テキストの単語の解析でのBags of wordsから着想を得たものになります。
| 2.学習器で判別について |
 | Bag of Visual Words
(ianlondon.github.comより引用) |
2.DeepLearningによる一般物体認識 | |
近年DeepLearningの発展により目覚ましい精度の向上が見られました。
AlexNetやGooglenet, ResNet等の多くの種類のDeepNeuralNetworkによってこれらの精度が改善されてました。 | DeepLeaningによる一般物体認識 |
DeepLearningを一躍有名にしたネットワーク。8層から構成されConvolution層などを含むことなどが特徴。
既存手法よりも精度が圧倒的に高かったため、注目が集めた。 | AlexNet |
この章を学んで新たに学べる
Comments
Reasons
知識: AlexNet
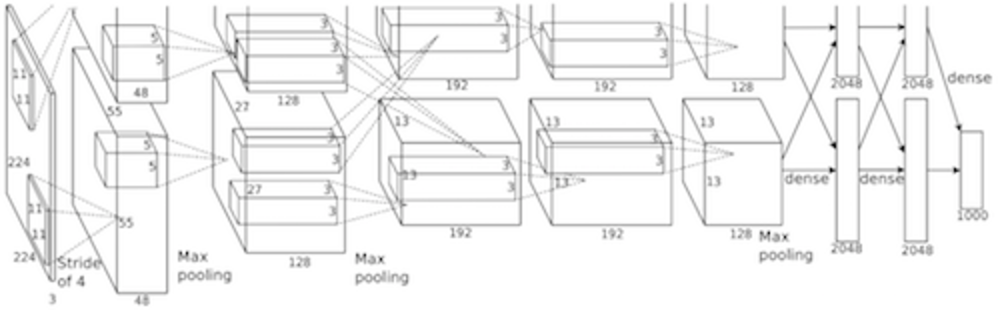
AlexNetはAlex,Hintonらによって開発されたCNN.全部で8層からなりうち5つがConvolution層.2012年画像分類の大会LSVRCにて好成績を残して注目される.